
DDI extension for CKAN for the Worldbank.
Features:
Requirement: This extensions runs on CKAN 2.3 or higher.
Use pip to install this plugin. This example installs it in
/home/www-data
source /home/www-data/pyenv/bin/activate
pip install -e git+https://github.com/liip/ckanext-ddi.git#egg=ckanext-ddi --src /home/www-data
cd /home/www-data/ckanext-ddi
pip install -r requirements.txt
python setup.py develop
Make sure to add ddi_schema, ddi_theme and nada_harvester to
ckan.plugins in your config file. If you don’t want to use the
frontend-part of this extension, you can omit the ddi_theme.
To use the nada_harvester, make sure the ckanext-harvest
extension is installed as
well.
Four options are available:
ckanext.ddi.config_file = /path/to/my/config.yml
ckanext.ddi.default_license = CC0-1.0
ckanext.ddi.allow_duplicates = True
ckanext.ddi.override_datasets = False
The config_file is simply the path to the DDI-specific configuration
of this extension (see below). The default_license allows a user to
configure a license that is used for all DDI imports, if the license is
not specified explicitly. The allow_duplicates option is used to
determine, if duplicate datasets are allowed or not. Duplicates are
determined by the unique id_number attribute (defaults to False).
With override_datasets you can specify, if you import a dataset that
already exists, if a new dataset should be created or if the existing
one should be overridden (defaults to False).
The display and structure of the DDI fields can be configured individually. A separate YAML config file is used for that.
There are 3 sections:
sections: describes different section, used to group together
fieldsvocabularies: describes availables controlled vocabularies, that
can be referencedfields: describes all fields, their type and how they are
displayed. Only the predefined fields can be used:
idnametitleurlauthorauthor_emailmaintainermaintainer_emaillicense_idcopyrightversionversion_notesnotestagsabbreviationstudy_typeseries_infoid_numberdescriptionproduction_typeproduction_dateabstractkind_of_dataunit_of_analysisdescription_of_scopecountrygeographic_coveragetime_period_covereduniverseprimary_investigatorother_producersfundingsampling_proceduredata_collection_datesaccess_authorityconditionscitation_requirementcontact_personscontact_persons_emailExample:
fields:
identification:
title:
type: text
visible: False
display: Title
url:
type: url
display_field: title
visible: True
display: Source
overview:
abstract:
type: markdown
visible: True
display: Abstract
kind_of_data:
type: vocabulary
visible: True
display: Kind of Data
contact:
contact_persons:
type: text
visible: False
display: Contact Persons
contact_persons_email:
type: email
display_field: contact_persons
visible: True
display: Contact person
internal_display: Contact Email
vocabularies:
kind_of_data:
- Sample survey data [ssd]
- Census/enumeration data [cen]
- Administrative records data [adm]
- Aggregate data [agg]
- Clinical data [cli]
- Event/transaction data [evn]
- Observation data/ratings [obs]
- Process-produced data [pro]
sections:
identification: Identification
overview: Overview
contact: Contact information
Based on this configuration the web UI is generated:
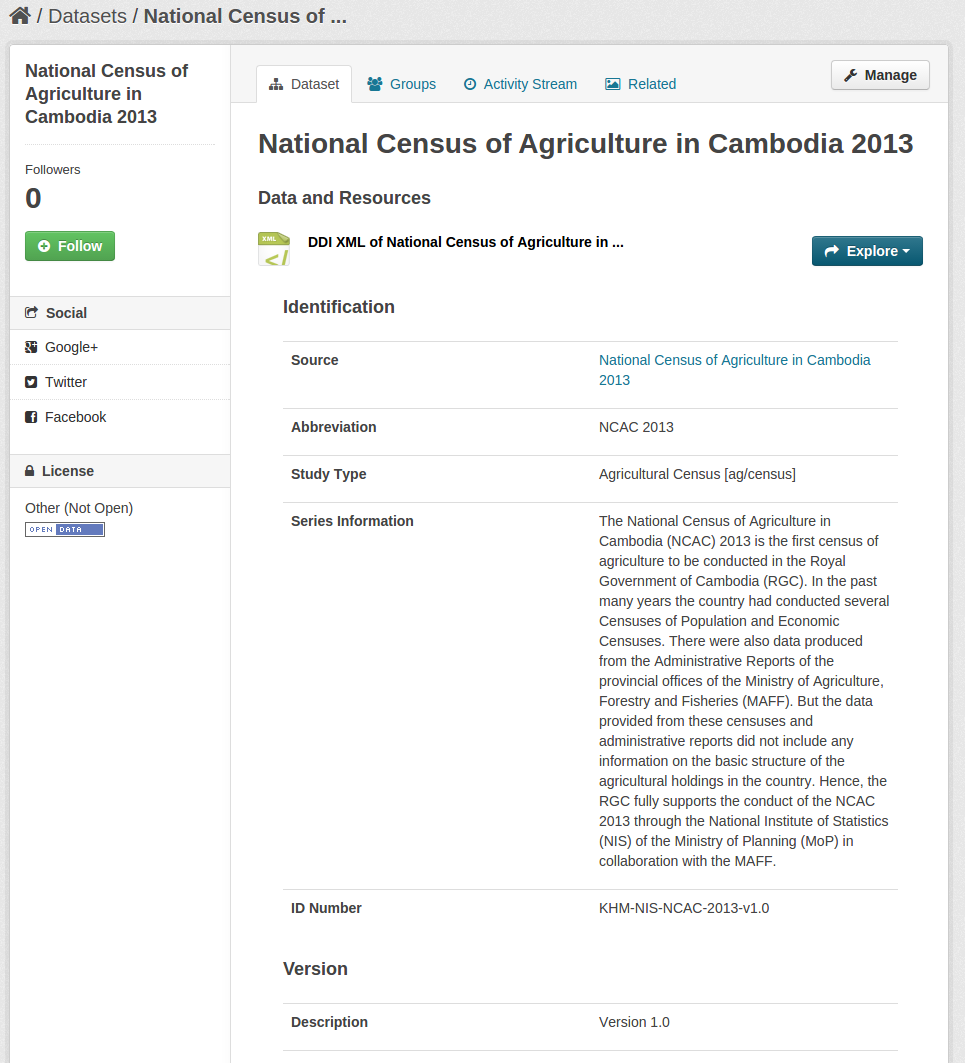
Data can be imported either via command line or using the web interface.
If you are logged in and you have the appropriate permissions, you find a new button “Import Dataset from DDI/XML” on the dataset page.
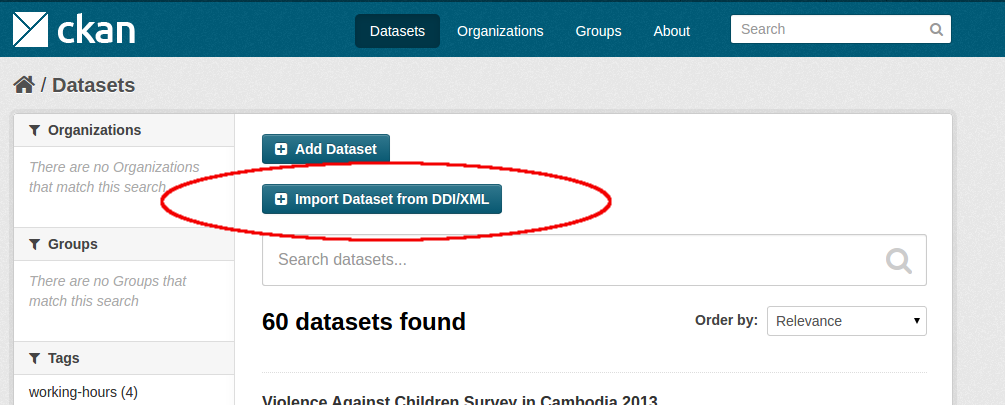
This buttons leads you to an import page, where a DDI XML can either be uploaded or specified as URL.
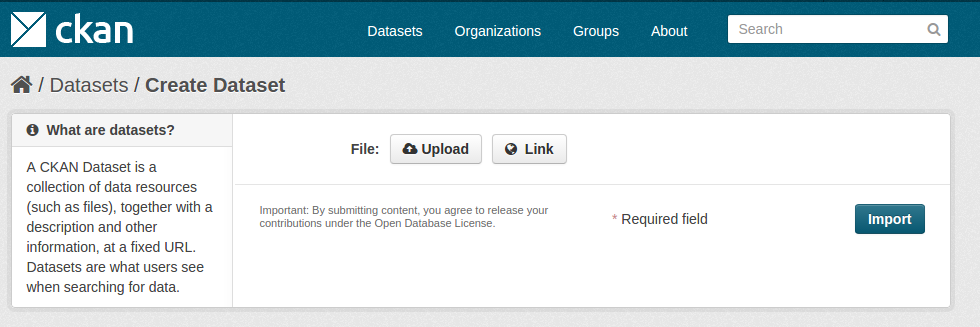
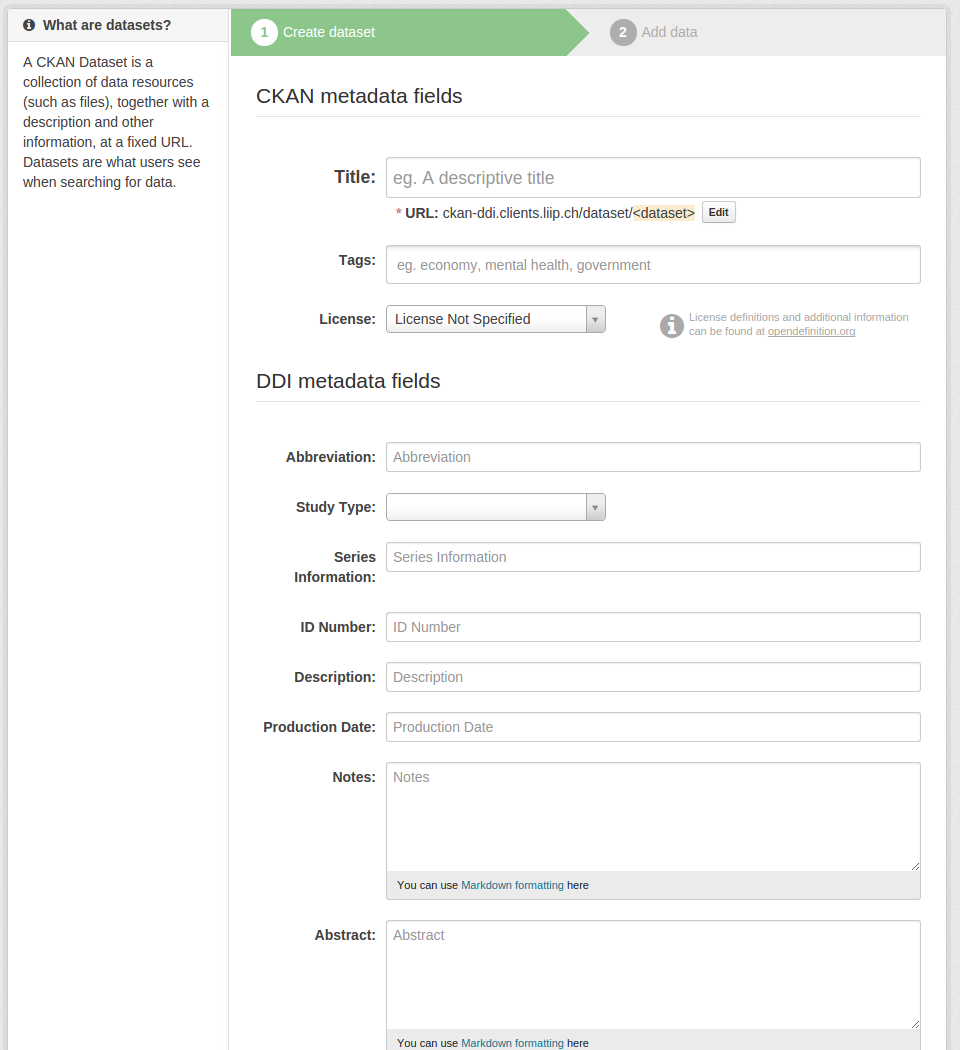
Instead of importing the DDI data, you can manually add datasets just like you would on any CKAN instance. The “Add Dataset” form is modified, so you can find all the fields from your DDI configuration (see above).
This plugin provides the possibility to import DDI XML files using a paster command.
source /home/www-data/pyenv/bin/activate
paster --plugin=ckanext-ddi ddi import <path_or_url> [<license>] -c <path to config file>
<path_or_url> is a required parameter and - as the name implies -
it can can either be a local file or a publicly accessible URL.<license> is an optional parameter to specify the license of the
dataset. Ideally this is a value from the configured license group
file.To add a harvester for a
NADA instance, you
should be logged in and visit /harvest on your CKAN installation (e.g.
http://my.ckaninstance.org/harvest).
There you can add a new harvest source with the type “NADA harvester for
DDI”.
In the URL field, specify the base URL of your NADA instance. If the start page of your NADA instance is my.nada-instance.org/index.php/home, then please specify http://my.nada-instance.org as the URL for the harvester.
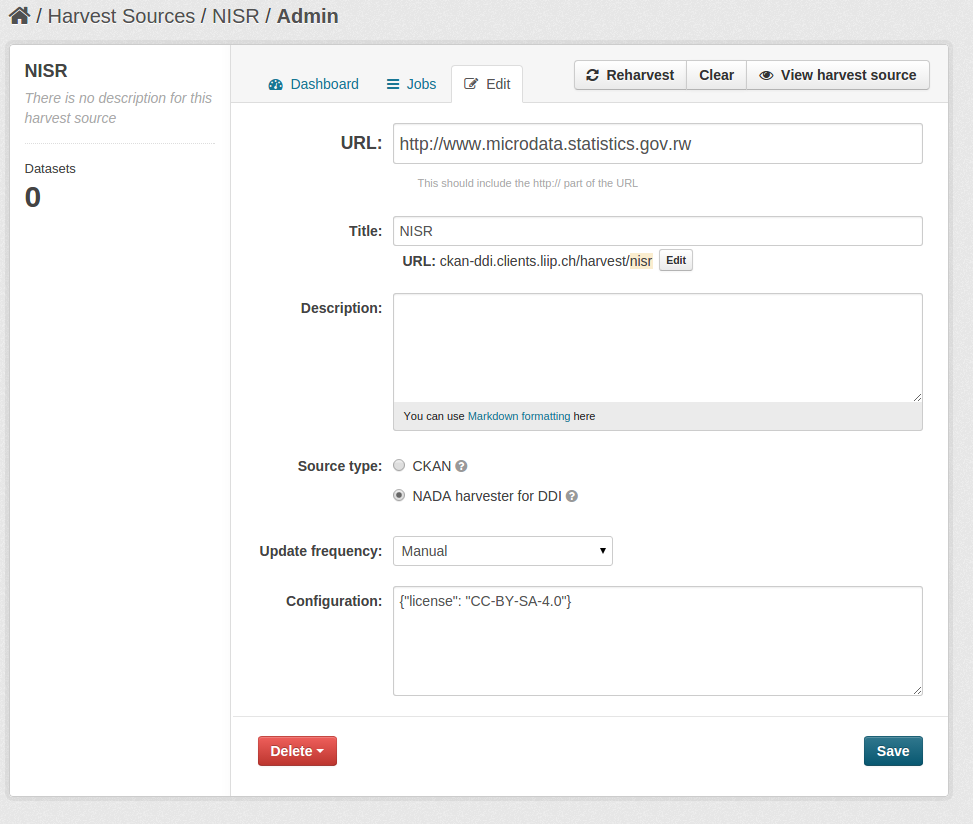
You can specify the configuration as JSON:
user: the CKAN user to perform the harvesting (default: harvest)license: A default license to apply to all harvested datasets
(default: empty). If this is not specified the config value
ckanext.ddi.default_license is used (see above).access_type: Parameter for NADA to specify the the data access
type of the datasets, that should be harvester (default:
public_use)Possible values for access_type:
"" (empty string, i.e. all data access types are allowed)"direct_access""public_use" (default)"licensed""data_enclave""data_external""no_data_available""open_data"JSON example:
{"user": "harvest", "access_type": "public_use", "license": "CC-BY-SA-4.0"}
This CKAN extensions uses flake8 to ensure basic code quality.
You can add a pre-commit hook when you have installed flake8:
flake8 --install-hook
Travis CI is used to check the code for all PRs.
This module was developed with support from the World Bank to provide a solution for National Statistical Offices (NSOs) that need to publish data on CKAN platforms.
 CKAN Extensions
CKAN Extensions